In the last post (Bayesian Data Analysis 1), I ran a Bayesian data analysis using a simple, first-principles approach. Armed with only the fact that a Poisson distribution is appropriate for modeling airplane accidents, Bayes Rule, and R, we got the correct answer to the problem through non-parametric simulation.
Before we get into precision and the other topics in the list of issues to explore, let’s tie up one loose end. I could have gotten the right answer for the wrong reason, so let’s look at the posterior distribution of 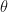

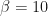
rgam <- rgamma (20000, 238, 10)
And then we can compare our posterior distribution with the official, parametric distribution:

Looks reasonably close (though biased by about 0.25) and it didn’t take a lot of fancy machinery to pull off. So why not use this method as our default? Why talk of things like conjugate priors and hyper parameters? And did we just get lucky with numeric precision because we only had 10 accidents and hence only 10 applications of Bayes Rule? Let’s cover that in the next posting, and finish this one with a graph of our answer (not

