As you probably know, I’m a big fan of R’s brms package, available from CRAN. In case you haven’t heard of it, brms is an R package by Paul-Christian Buerkner that implements Bayesian regression of all types using an extension of R’s formula specification that will be familiar to users of lm, glm, and lmer. Under the hood, it translates the formula into Stan code, Stan translates this to C++, your system’s C++ compiler is used to compile the result and it’s run.

brms is impressive in its own right. But also impressive is how it continues to add capabilities and the breadth of Buerkner’s vision for it. I last posted something way back on version 0.8, when brms gained the ability to do non-linear regression, but now we’re up to version 1.1, with 1.2 around the corner. What’s been added since 0.8, you may ask? Here are a few highlights:


 Prior
Prior  Likelihood. I didn’t have to know anything about conjugate priors, hyperparameters, sufficient statistics, parametric forms, or anything beyond the basics. I got a reasonable posterior for
Likelihood. I didn’t have to know anything about conjugate priors, hyperparameters, sufficient statistics, parametric forms, or anything beyond the basics. I got a reasonable posterior for 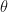 and used that to find the correct answer. Why go beyond this?
and used that to find the correct answer. Why go beyond this?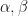 ) distribution, and given our series of
) distribution, and given our series of  accident counts and an initial (posterior)
accident counts and an initial (posterior)  and
and 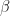 , the posterior density is Gamma (
, the posterior density is Gamma ( )
) and
and 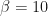 . (More on this in the next posting.) So I simulated out 20,000 samples from that distribution:
. (More on this in the next posting.) So I simulated out 20,000 samples from that distribution:

 distribution. The data is :
distribution. The data is : . Plotting the theta’s together:
. Plotting the theta’s together:
