This is the fourth article in the series, where the techiness builds to a crescendo. If this is too statistical/programming geeky for you, the next posting will return to a more investigative and analytical flavor. Last time, we looked at a fixed-effects model:
m.fe <- lm (dollars ~ 1 + regime + ratetemp * I(dca - 55))
which looks like a plausible model and whose parameters are all statistically significant. A question that might arise is: why not use a hierarchical (AKA multilevel, mixed-effects) model instead? While we’re at it, why not go full-on Bayesian as well? It just so happens that there is a great new tool called Stan which fits the bill and which also has an rstan package for R.

Stan is developed by the great folks on the Stan development team, and has been widely promoted by statistician Andrew Gelman. It was originally developed to solve some problems faster than BUGS or Martyn Plummer‘s JAGS, using HMC rather than Gibbs sampling. (In particular, an algorithm called NUTS: the No U-Turn Sampler.)
So let’s get started! With Stan and rstan installed, we specify our model in R:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| stan.code <- | |
| "data | |
| { | |
| int cut ; | |
| int nu ; | |
| int N ; | |
| real dollars[N] ; | |
| real dca[N] ; | |
| int rate[N] ; | |
| int regime[N] ; | |
| } | |
| transformed data | |
| { | |
| real dcaX[N] ; | |
| int ratetemp[N] ; | |
| for (n in 1:N) | |
| { | |
| dcaX[n] <- dca[n] – cut ; | |
| if (dcaX[n] < 0) | |
| { ratetemp[n] <- 1 ; } | |
| else if (rate[n] == 1) | |
| { ratetemp[n] <- 2 ; } | |
| else | |
| { ratetemp[n] <- 3 ; } | |
| } | |
| } | |
| parameters | |
| { | |
| real alpha[3] ; // intercept, per ratetemp | |
| real alpha_alpha ; | |
| real alpha_sigma ; | |
| real beta[3] ; // slope, per ratetemp | |
| real beta_alpha ; | |
| real beta_sigma ; | |
| real gamma[5] ; // intercept, per regime | |
| real gamma_alpha ; | |
| real gamma_sigma ; | |
| real sigma[3] ; | |
| real sigma_alpha ; | |
| real sigma_sigma ; | |
| } | |
| model | |
| { | |
| alpha ~ normal (alpha_alpha, alpha_sigma) ; | |
| alpha_alpha ~ normal (570, 150) ; | |
| alpha_sigma ~ cauchy (0, 70) ; | |
| beta ~ normal (beta_alpha, beta_sigma) ; | |
| beta_alpha ~ normal (0, 15) ; | |
| beta_sigma ~ cauchy (0, 10) ; | |
| gamma ~ normal (gamma_alpha, gamma_sigma) ; | |
| gamma_alpha ~ normal (0, 5) ; | |
| gamma_sigma ~ cauchy (0, 80) ; | |
| sigma ~ cauchy (sigma_alpha, sigma_sigma) ; | |
| sigma_alpha ~ cauchy (0, 40) ; | |
| sigma_sigma ~ cauchy (0, 5) ; | |
| for (n in 1:N) | |
| { | |
| dollars[n] ~ normal (gamma[regime[n]] + alpha[ratetemp[n]] + beta[ratetemp[n]] * dcaX[n], sigma[ratetemp[n]]) ; | |
| // dollars[n] ~ student_t (nu, gamma[regime[n]] + alpha[ratetemp[n]] + beta[ratetemp[n]] * dcaX[n], sigma[ratetemp[n]]) ; | |
| } | |
| } | |
| " |
which is a hierarchical version of our fixed-effects model. For those familiar with lmer‘s formulas, this would be specified as something like lmer (dollars ~ 1 + (1 | regime) + (1 + I(dca-cut) | ratetemp)).
The data section specifies the data that will be passed in to Stan. The transformed data section is where I center the temperature (dca) at our 55-degree (an input to Stan, actually) set point, and create ratetemp which combines the seasonal rate and whether the average monthly temperature is above or below the set point. I could pre-center dca in R before passing it to Stan, but doing the centering in Stan keeps everything together in the model for clarity. Similarly, I already have a ratetemp variable in R, but if I modify the cut point, the temp part of ratetemp might change, so keeping the calculation in Stan makes things clearer and less error-prone.
The parameters section specifies the modeled parameters, which Stan calculates via MCMC sampling. And last, the model section specifies the model itself, which specifies how the data and parameters are related. Note that this is a Bayesian model, where parameters have priors and we’re calculating the posterior distributions of the parameters. It’s also a hierarchical model, where some of the priors are themselves modeled, though not a nested hierarchical model since regime is not nested in ratetemp and vice versa. Note that unlike BUGS and JAGS, the Stan code is actually compiled and executed — it’s not just a kind of model specification. The C++-style comment in the for loop is commenting out a more-robust student’s t-based alternative fit.
I started with a simple regression model, tested it, compared it to lm or lmer, and then expanded it until I reached the model I wanted. Hopefully, you can see how powerful modeling in Stan is. Now that the model is specified, we put the data into a list (in R):
stan.list <- list (cut=55, nu=9, N=length (elect5$dca), dollars=elect5$dollars, dca=elect5$dca, rate=as.integer (elect5$rate), regime=as.integer (elect5$regime))
which supplies all of the variables specified in the data section of the model. (Actually, it supplies nu, which is not used in the current model, but Stan has no problem with unused variables.) To compile the model into C++, then compile and run the sampler, we use stan:
library (rstan)
stan.model <- stan (model_code=stan.code, model_name=paste ("Electricity", stan.list$cut), data=stan.list, iter=300000)
which will print out updates as the code is compiled, then at each 10% of the way through the sampling of each chain. (The default is to run 4 chains, each starting at a different initial value.) The result is displayed with stan.model:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Inference for Stan model: Electricity 55. | |
| 4 chains, each with iter=3e+05; warmup=150000; thin=1; | |
| post-warmup draws per chain=150000, total post-warmup draws=6e+05. | |
| mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat | |
| alpha[1] 446.4 1.1 31.7 385.0 427.1 445.6 464.9 509.7 810 1 | |
| alpha[2] 486.5 0.3 31.3 425.6 467.5 486.3 504.3 550.5 9341 1 | |
| alpha[3] 588.3 0.3 41.3 507.6 562.0 588.2 614.1 671.4 23192 1 | |
| alpha_alpha 513.7 0.4 59.9 400.6 477.7 510.0 547.8 644.4 22189 1 | |
| alpha_sigma 95.1 1.1 64.5 33.7 57.0 78.8 111.9 255.4 3251 1 | |
| beta[1] -2.9 0.0 0.7 -4.3 -3.4 -2.9 -2.5 -0.9 237 1 | |
| beta[2] 5.8 0.0 1.2 3.4 5.0 5.8 6.6 8.1 32546 1 | |
| beta[3] 5.1 0.0 1.2 2.7 4.3 5.1 6.0 7.6 2223 1 | |
| beta_alpha 2.5 0.1 4.7 -7.4 0.2 2.5 5.0 11.5 1295 1 | |
| beta_sigma 7.6 0.1 5.4 2.6 4.5 6.2 9.0 21.0 10012 1 | |
| gamma[1] -77.6 0.9 30.9 -140.8 -95.7 -76.5 -58.9 -18.7 1285 1 | |
| gamma[2] 39.8 0.3 30.1 -21.8 23.3 39.9 57.3 99.7 9775 1 | |
| gamma[3] -20.0 0.5 30.1 -81.6 -38.0 -19.5 -2.3 38.9 3468 1 | |
| gamma[4] 38.0 0.2 32.0 -25.7 19.5 37.2 57.1 101.9 20164 1 | |
| gamma[5] 6.0 0.3 30.0 -55.6 -11.7 6.3 23.5 64.7 9185 1 | |
| gamma_alpha -0.3 0.2 5.1 -9.8 -3.7 -0.2 3.2 9.6 508 1 | |
| gamma_sigma 61.5 0.2 27.9 29.5 43.7 54.5 71.7 133.0 21382 1 | |
| sigma[1] 19.7 0.1 2.9 14.3 17.8 19.6 21.6 25.9 1166 1 | |
| sigma[2] 22.2 0.0 3.5 16.8 19.8 21.7 23.9 30.7 33349 1 | |
| sigma[3] 19.9 0.1 3.3 13.9 17.8 19.7 21.9 27.0 3124 1 | |
| sigma_alpha 20.4 0.0 3.6 13.7 18.4 20.3 22.4 27.9 5144 1 | |
| sigma_sigma 2.8 0.1 3.4 0.1 0.8 1.9 3.6 11.3 3118 1 | |
| lp__ -255.8 0.0 4.2 -264.9 -258.4 -255.5 -253.0 -248.3 14719 1 | |
| Samples were drawn using NUTS2 at Thu Jun 20 23:06:33 2013. | |
| For each parameter, n_eff is a crude measure of effective sample size, | |
| and Rhat is the potential scale reduction factor on split chains (at | |
| convergence, Rhat=1). |
The values only display one significant digit to keep it small, but to display more digits, you can print (stan.model, digits_summary=3). The Rhat looks like things converged, but we can do several diagnostic checks (there may be more efficient ways, but this worked for me):
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| library (coda) | |
| gelman.diag (mcmc.list (mcmc (extract (stan.model, pars="alpha", permuted=F)[,1,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,2,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,3,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,4,1]))) | |
| heidel.diag (mcmc.list (mcmc (extract (stan.model, pars="alpha", permuted=F)[,1,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,2,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,3,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,4,1]))) | |
| geweke.diag (mcmc.list (mcmc (extract (stan.model, pars="alpha", permuted=F)[,1,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,2,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,3,1]), | |
| mcmc (extract (stan.model, pars="alpha", permuted=F)[,4,1]))) |
All of which seem to confirm that the sampling converged properly, and the results, above, are meaningful. The plot at the top of this posting reflects the results of this model. I calculated the 95% predictive credible intervals based on the current regime (R5) with:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| stan.model.s <- summary (stan.model) | |
| a1 <- rnorm (3000, stan.model.s$summary["alpha[1]","mean"], stan.model.s$summary["alpha[1]","sd"]) # low-cooler intercepts | |
| b1 <- rnorm (3000, stan.model.s$summary["beta[1]", "mean"], stan.model.s$summary["beta[1]", "sd"]) # low-cooler slopes | |
| s1 <- rnorm (3000, stan.model.s$summary["sigma[1]","mean"], stan.model.s$summary["sigma[1]","sd"]) # low-cooler noise | |
| g1 <- rnorm (3000, stan.model.s$summary["gamma[5]","mean"], stan.model.s$summary["gamma[5]","sd"]) # low-cooler regime R5 | |
| ci1 <- foreach (x=30:55, .combine="cbind") %do% c(x, quantile (a1 + s1 + g1 + b1 * (x – 55), c(0.025, 0.5, 0.975))) | |
| a2 <- rnorm (3000, stan.model.s$summary["alpha[2]","mean"], stan.model.s$summary["alpha[2]","sd"]) # low-warmer intercepts | |
| b2 <- rnorm (3000, stan.model.s$summary["beta[2]", "mean"], stan.model.s$summary["beta[2]", "sd"]) # low-warmer slopes | |
| s2 <- rnorm (3000, stan.model.s$summary["sigma[2]","mean"], stan.model.s$summary["sigma[2]","sd"]) # low-warmer noise | |
| g2 <- rnorm (3000, stan.model.s$summary["gamma[5]","mean"], stan.model.s$summary["gamma[5]","sd"]) # low-warmer regime R5 | |
| ci2 <- foreach (x=55:72, .combine="cbind") %do% c(x, quantile (a2 + s2 + g2 + b2 * (x – 55), c(0.025, 0.5, 0.975))) | |
| a3 <- rnorm (3000, stan.model.s$summary["alpha[3]","mean"], stan.model.s$summary["alpha[3]","sd"]) # high-warmer intercepts | |
| b3 <- rnorm (3000, stan.model.s$summary["beta[3]", "mean"], stan.model.s$summary["beta[3]", "sd"]) # high-warmer slopes | |
| s3 <- rnorm (3000, stan.model.s$summary["sigma[3]","mean"], stan.model.s$summary["sigma[3]","sd"]) # high-warmer noise | |
| g3 <- rnorm (3000, stan.model.s$summary["gamma[5]","mean"], stan.model.s$summary["gamma[5]","sd"]) # high-warmer regime R5 | |
| ci3 <- foreach (x=70:85, .combine="cbind") %do% c(x, quantile (a3 + s3 + g3 + b3 * (x – 55), c(0.025, 0.5, 0.975))) |
The lines may not look centered on the data, since the regime offsets varied from -77 (R1) to around 38 (R2 and R4), and R5‘s offset is about 6. (Which, by the way, says that the regimes have varied by about 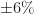
Hopefully this provides a solid baseline model and has shown you powerful and flexible Bayesian tools R and Stan can be. In the next post, we’ll look a bit more closely at some of the results, and see what we’ve gained by doing a Bayesian.
