This is the story of a condominium association in Northern Virginia, which was in the midst of transforming their budget. In the early days of the association they didn’t have an operational cash reserve built up, so they had to make budget categories a bit oversized, “just in case”. As time went on, they saved the cash from their over-estimates, and eventually arrived at the place where they could set tighter budgets and depend on their cash savings if the budget were exceeded.
In the process of reviewing various categories, they came to “Utilities”, which lumped water, sewage, gas, and electricity all together. They decided to break it down into individual utilities, but when they started with electricity, no one actually knew how much was used nor how much it cost. The General Manager had dutifully filed away monthly bills from Dominion, but didn’t have a spreadsheet. They needed a data analyst, and I was all over it.
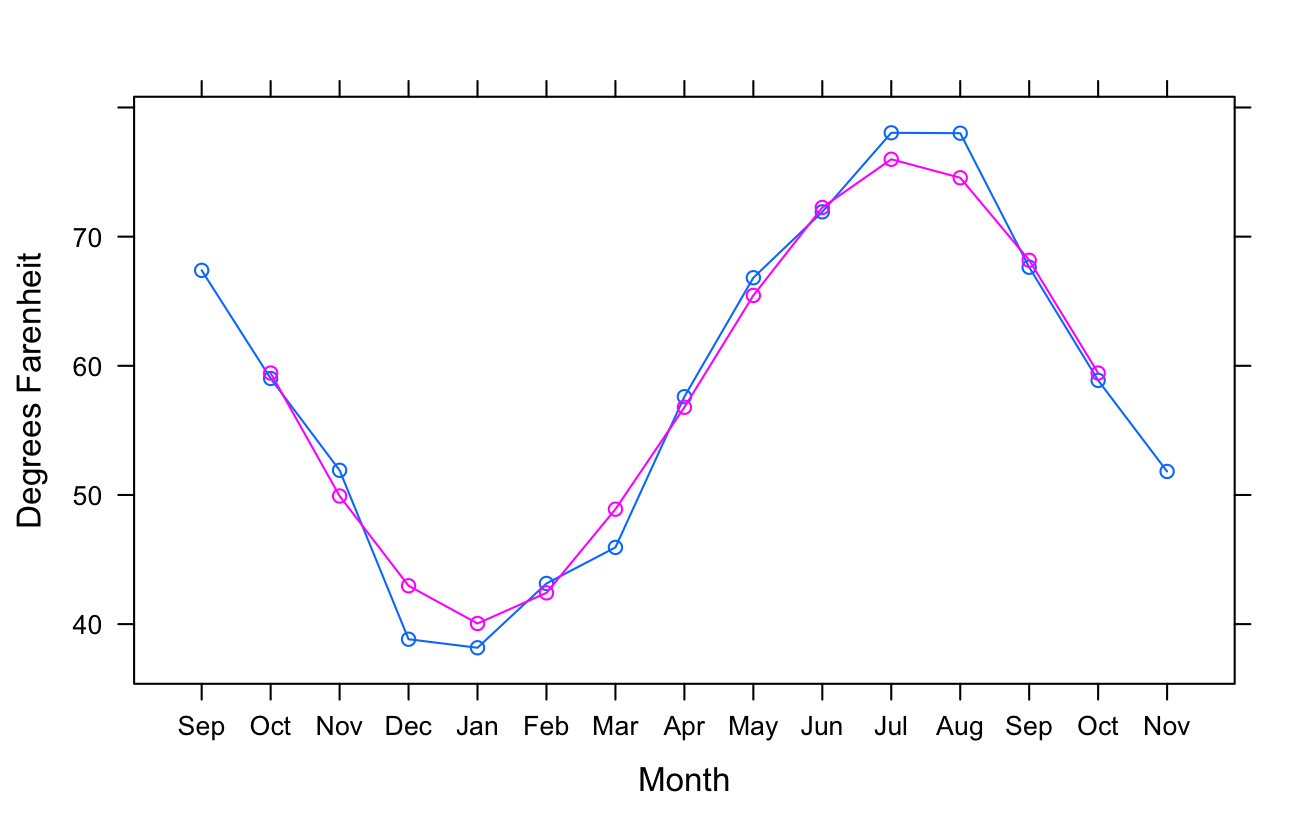
In the next four or five postings, I want to show some of the details of my investigation of electricity expenses. I hope it will be an interesting look at the kinds of things that happen in the real world, not just textbooks. Oh, by the way, it turns out that electricity was the single largest operating expense of the association. Here’s a graph of average expenditures, brought up to the present:
 Continue reading →
Continue reading →