I’m always intrigued by techniques that have cool names: Support Vector Machines, State Space Models, Spectral Clustering, and an old favorite Hidden Markov Models (HMM’s). While going through some of my notes, I stumbled onto a fun experiment with HMM’s where you feed a bunch of English text into a two-state HMM and it will (tend to) discover what letters are vowels.
The first thing we’ll need is a bunch of English text. You may have some sitting around, but the classic dataset is the Brown Corpus, which you can download and use readChar to pull out a section 40-50,000 characters long. (The Brown Corpus’ words file is 5.7 million characters long.) Say we have this string in corpus. We can lowercase everything and replace everything outside of A-Z with an underscore, and load the HMM library:
a <- unlist (strsplit (gsub ("[^a-z]", "_", tolower (corpus)), ""))
letter.labels=c("_", letters)
library (HMM)
library (lattice)
There are other HMM packages that you might prefer, including hmm.discnp and RHmm, but I’ve chosen to use HMM for this entry. Now, let’s prepare an HMM with two hidden states and our alphabet. You can let the start, transition, and emissions probabilities default, but I’ve had much better luck if the probabilities are not all perfectly flat, so I randomize them a bit:
prob <- function (x) {x / sum (x)} # Makes it a probability (it sums to 1)
hmm <- initHMM (c("A", "B"), letter.labels, startProbs=(prob (runif (2))),
transProbs=apply (matrix (runif (4), 2), 1, prob),
emissionProbs=apply (matrix (runif (54), 2), 1, prob))
Then, we use the Baum Welch algorithm to update the probabilities based on repeated iteration over the corpus:
system.time (a.bw <- baumWelch (hmm, a))
CAUTION: On my laptop, this took about 15 minutes. The default maximum number of iterations is 100, and you can try smaller numbers to see if you’re on the right track:
system.time (a.bw <- baumWelch (hmm, a, 5))
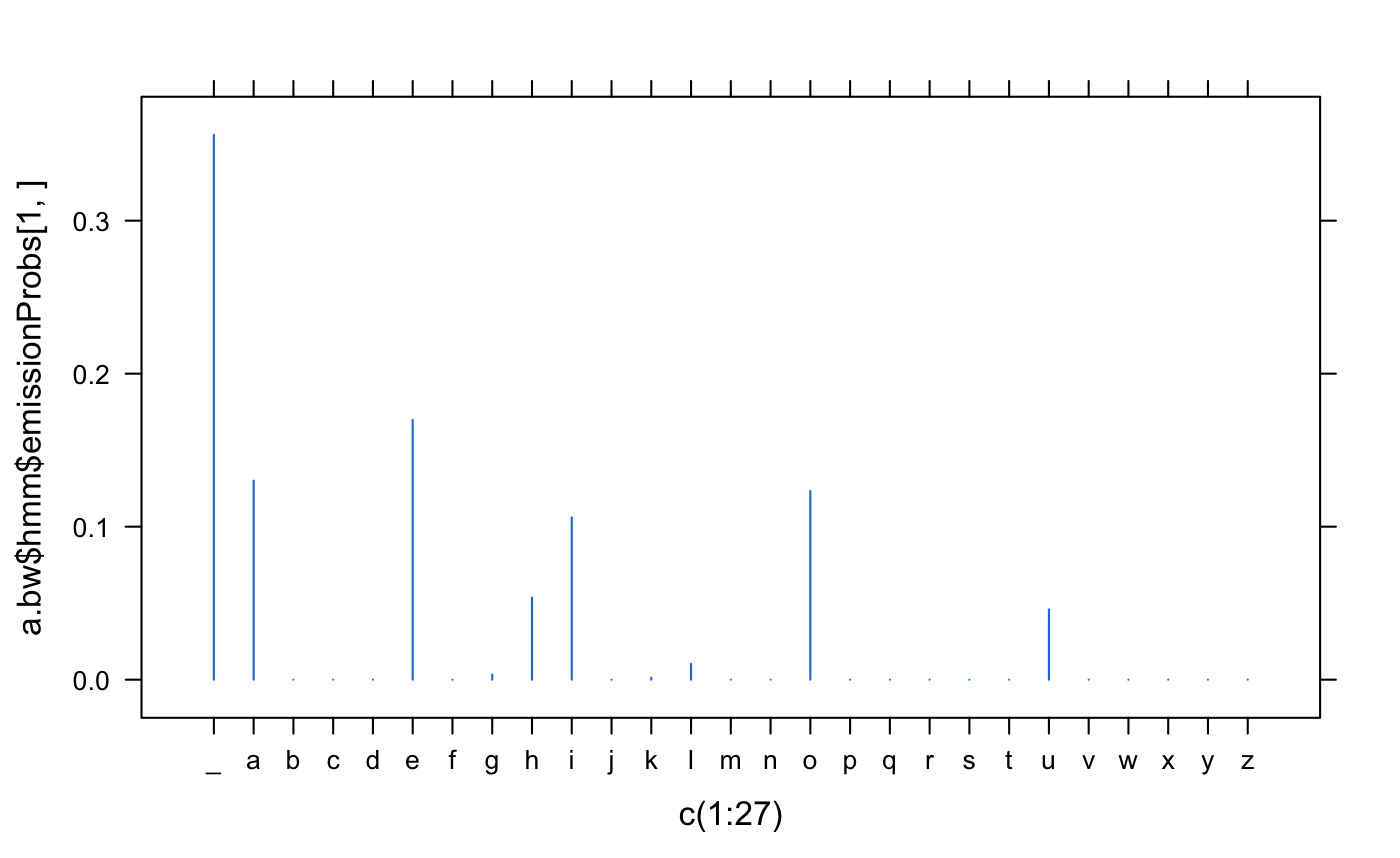
would iterate at most 5 times. The results won’t be nearly as good as going, say, 50 iterations but you should see one of the two classes having larger bumps at the vowels and space. The graph at the top of the article was generated by:
xyplot (a.bw$hmm$emissionProbs[1,] ~ c(1:27), scales=list(x=list(at=1:27, labels=colnames (a.bw$hmm$emissionProbs))), type=”h”)
and the other state is:
xyplot (a.bw$hmm$emissionProbs[2,] ~ c(1:27), scales=list(x=list(at=1:27, labels=colnames (a.bw$hmm$emissionProbs))), type=”h”)
You can’t tell in advance which of the two states will reflect the vowels (and space). You can add more states and see what you get. From the reference I found, below, if you’re smart and patient you can find sensible interpretations for up to 12 states. You can get better results with more text, and for more states you may well need it.
It turns out that HMM’s are related to the Kalman Filter and are more or less discrete versions of State Space Models.
The idea for this experiment originally came from the paper, “Hidden Markov models for English”, by R. L. Cave and L. P. Neuwirth, which was in Hidden Markov Models for Speech, October 1980. I haven’t found that paper, but Prof. Mark Stamp wrote a nice introduction to HMM’s, and a student of his, Tun Tao Tsai, wrote a thesis around 2005 which mentions more details of the Cave and Neuwirth paper.

Hello,
I am currently a thesis student at Middlebury College and am trying to run a similar example in R. A question- how did you clean up the Brown Corpus? I am having trouble getting rid of the punctuation tags.
Thanks in advance for any and all advice.
Raquel, I have to apologize that it’s been a while back and I don’t remember what I did to preprocess things. I’m pretty sure that anything I did was done through R’s
tmpackage, which you might find useful if you haven’t already looked into it. I hope you’re successful!An HMM utility of my own (written in C++) fits the first 50K symbols of the “Brown Corpus” in about 2 seconds (on a fast laptop) ;)
Hi,
About HMM packages, would you know a python package which is able to learn HMM from sequencies of symbols AND compute likelihood of new sequencies of symbols according to the learnt HMM?
I am currently struggling doing that with the hmmlearn package.
Thanks a lot,
Yvan
Pingback: Getting Started with Hidden Markov Models in R ← Patient 2 Earn
You’re right, DTW gets bonus points for the sci-fi sound.
Talking about methods with cool names, how about “Dynamic Time Warping”:
http://en.wikipedia.org/wiki/Dynamic_time_warping
;-)
Cheers,
Andrej