You’ve probably noticed that Deep Learning is all the rage right now. AlphaGo has beaten the world champion at Go, you can google cat photos and be sure you won’t accidentally get photos of canines, and many other near-miraculous feats: all enabled by Deep Learning with neural nets. (I am thinking of coining the phrase “laminar learning” to add some panache to old-school non-deep learning.)
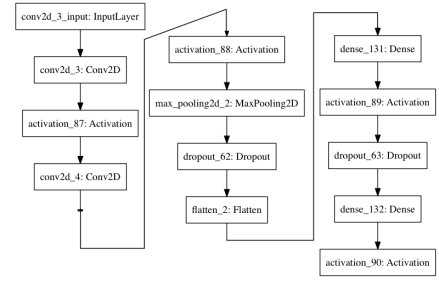
I do a lot of my work in R, and it turns out that not one but two R packages have recently been released that enable R users to use the famous Python-based deep learning package, Keras: keras and kerasR.