In the first posting of this series, I simply applied Bayes Rule repeatedly: Posterior 

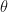
Well, first, there’s really no good way for me to communicate my
Second, my posterior density is discrete. This works reasonably well for the exercise I attempted, but it’s still a discrete approximation which is less precise and can suffer from simulation-related issues (number of samples, etc) that have nothing to do with my proposed model.
Third, if an analytical method can be used, it may be possible to directly calculate a final posterior without repeated applications of Bayes Rule. As I mentioned in the previous posting, Gelman got an answer of Gamma(238, 10) analytically, not through approximations and simulation. If we look in Wikipedia, we can find that the conjugate prior for 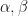


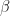

Thus, starting with priors for the hyperameters (
Let’s examine the steps of using Bayes Rule a little more closely. The prior doesn’t need to have any special distribution. In fact, it should reflect any knowledge we might have regarding the problem at hand. The likelihood, however, will have a distribution specific to the model we are using: in this exercise it was Poisson which is appropriate for the number of unrelated accidents in a year.
Multiplying these two, point-by-point on my sampled grid creates a posterior which is a compromise between a parametric and an arbitrary distribution, and this semi-arbitrary posterior is then used as the prior for the next datum. When iterated over the data, the likelihood influences the posterior more and more, of course. In the end, as we showed in the previous posting, the result is very close to the parametric Gamma (238, 10) that Gelman found. We could use various methods to estimate the parameters
Of course, this depends on the Gamma distribution being a reasonable distribution for the problem at hand. It’s one more part of our model, and models are only approximations, but they should be principled and reasonably-accurate approximations at the end of the day. Next time, let’s consider some simulation-related issues.
